Merge pull request #959 from Alexander-N/allow-threads
User Guide: Rewrite parallelism chapter
This commit is contained in:
commit
34a5e8c30b
|
|
@ -137,7 +137,6 @@ about this topic.
|
|||
|
||||
## Examples
|
||||
|
||||
* [examples/word-count](examples/word-count) _Counting the occurrences of a word in a text file_
|
||||
* [hyperjson](https://github.com/mre/hyperjson) _A hyper-fast Python module for reading/writing JSON data using Rust's serde-json_
|
||||
* [html-py-ever](https://github.com/PyO3/setuptools-rust/tree/master/html-py-ever) _Using [html5ever](https://github.com/servo/html5ever) through [kuchiki](https://github.com/kuchiki-rs/kuchiki) to speed up html parsing and css-selecting._
|
||||
* [point-process](https://github.com/ManifoldFR/point-process-rust/tree/master/pylib) _High level API for pointprocesses as a Python library_
|
||||
|
|
|
|||
|
|
@ -82,7 +82,7 @@ setup(
|
|||
"Operating System :: MacOS :: MacOS X",
|
||||
],
|
||||
packages=["word_count"],
|
||||
rust_extensions=[RustExtension("word_count.word_count", "Cargo.toml", debug=True)],
|
||||
rust_extensions=[RustExtension("word_count.word_count", "Cargo.toml", debug=False)],
|
||||
install_requires=install_requires,
|
||||
tests_require=tests_require,
|
||||
setup_requires=setup_requires,
|
||||
|
|
|
|||
|
|
@ -4,45 +4,25 @@
|
|||
use pyo3::prelude::*;
|
||||
use pyo3::wrap_pyfunction;
|
||||
use rayon::prelude::*;
|
||||
use std::fs;
|
||||
use std::path::PathBuf;
|
||||
|
||||
/// Represents a file that can be searched
|
||||
#[pyclass(module = "word_count")]
|
||||
struct WordCounter {
|
||||
path: PathBuf,
|
||||
/// Searches for the word, parallelized by rayon
|
||||
#[pyfunction]
|
||||
fn search(contents: &str, needle: &str) -> usize {
|
||||
contents
|
||||
.par_lines()
|
||||
.map(|line| count_line(line, needle))
|
||||
.sum()
|
||||
}
|
||||
|
||||
#[pymethods]
|
||||
impl WordCounter {
|
||||
#[new]
|
||||
fn new(path: String) -> Self {
|
||||
WordCounter {
|
||||
path: PathBuf::from(path),
|
||||
}
|
||||
}
|
||||
/// Searches for a word in a classic sequential fashion
|
||||
#[pyfunction]
|
||||
fn search_sequential(contents: &str, needle: &str) -> usize {
|
||||
contents.lines().map(|line| count_line(line, needle)).sum()
|
||||
}
|
||||
|
||||
/// Searches for the word, parallelized by rayon
|
||||
fn search(&self, py: Python<'_>, search: String) -> PyResult<usize> {
|
||||
let contents = fs::read_to_string(&self.path)?;
|
||||
|
||||
let count = py.allow_threads(move || {
|
||||
contents
|
||||
.par_lines()
|
||||
.map(|line| count_line(line, &search))
|
||||
.sum()
|
||||
});
|
||||
Ok(count)
|
||||
}
|
||||
|
||||
/// Searches for a word in a classic sequential fashion
|
||||
fn search_sequential(&self, needle: String) -> PyResult<usize> {
|
||||
let contents = fs::read_to_string(&self.path)?;
|
||||
|
||||
let result = contents.lines().map(|line| count_line(line, &needle)).sum();
|
||||
|
||||
Ok(result)
|
||||
}
|
||||
#[pyfunction]
|
||||
fn search_sequential_allow_threads(py: Python, contents: &str, needle: &str) -> usize {
|
||||
py.allow_threads(|| search_sequential(contents, needle))
|
||||
}
|
||||
|
||||
fn matches(word: &str, needle: &str) -> bool {
|
||||
|
|
@ -63,7 +43,6 @@ fn matches(word: &str, needle: &str) -> bool {
|
|||
}
|
||||
|
||||
/// Count the occurences of needle in line, case insensitive
|
||||
#[pyfunction]
|
||||
fn count_line(line: &str, needle: &str) -> usize {
|
||||
let mut total = 0;
|
||||
for word in line.split(' ') {
|
||||
|
|
@ -76,8 +55,9 @@ fn count_line(line: &str, needle: &str) -> usize {
|
|||
|
||||
#[pymodule]
|
||||
fn word_count(_py: Python<'_>, m: &PyModule) -> PyResult<()> {
|
||||
m.add_wrapped(wrap_pyfunction!(count_line))?;
|
||||
m.add_class::<WordCounter>()?;
|
||||
m.add_wrapped(wrap_pyfunction!(search))?;
|
||||
m.add_wrapped(wrap_pyfunction!(search_sequential))?;
|
||||
m.add_wrapped(wrap_pyfunction!(search_sequential_allow_threads))?;
|
||||
|
||||
Ok(())
|
||||
}
|
||||
|
|
|
|||
|
|
@ -1,15 +1,16 @@
|
|||
# -*- coding: utf-8 -*-
|
||||
import os
|
||||
from concurrent.futures import ThreadPoolExecutor
|
||||
|
||||
import pytest
|
||||
|
||||
import word_count
|
||||
|
||||
current_dir = os.path.abspath(os.path.dirname(__file__))
|
||||
path = os.path.join(current_dir, "zen-of-python.txt")
|
||||
|
||||
|
||||
@pytest.fixture(scope="session", autouse=True)
|
||||
def textfile():
|
||||
@pytest.fixture(scope="session")
|
||||
def contents() -> str:
|
||||
text = """
|
||||
The Zen of Python, by Tim Peters
|
||||
|
||||
|
|
@ -33,23 +34,39 @@ If the implementation is hard to explain, it's a bad idea.
|
|||
If the implementation is easy to explain, it may be a good idea.
|
||||
Namespaces are one honking great idea -- let's do more of those!
|
||||
"""
|
||||
|
||||
with open(path, "w") as f:
|
||||
f.write(text * 1000)
|
||||
yield
|
||||
os.remove(path)
|
||||
return text * 1000
|
||||
|
||||
|
||||
def test_word_count_rust_parallel(benchmark):
|
||||
count = benchmark(word_count.WordCounter(path).search, "is")
|
||||
def test_word_count_rust_parallel(benchmark, contents):
|
||||
count = benchmark(word_count.search, contents, "is")
|
||||
assert count == 10000
|
||||
|
||||
|
||||
def test_word_count_rust_sequential(benchmark):
|
||||
count = benchmark(word_count.WordCounter(path).search_sequential, "is")
|
||||
def test_word_count_rust_sequential(benchmark, contents):
|
||||
count = benchmark(word_count.search_sequential, contents, "is")
|
||||
assert count == 10000
|
||||
|
||||
|
||||
def test_word_count_python_sequential(benchmark):
|
||||
count = benchmark(word_count.search_py, path, "is")
|
||||
def test_word_count_python_sequential(benchmark, contents):
|
||||
count = benchmark(word_count.search_py, contents, "is")
|
||||
assert count == 10000
|
||||
|
||||
|
||||
def run_rust_sequential_twice(
|
||||
executor: ThreadPoolExecutor, contents: str, needle: str
|
||||
) -> int:
|
||||
future_1 = executor.submit(
|
||||
word_count.search_sequential_allow_threads, contents, needle
|
||||
)
|
||||
future_2 = executor.submit(
|
||||
word_count.search_sequential_allow_threads, contents, needle
|
||||
)
|
||||
result_1 = future_1.result()
|
||||
result_2 = future_2.result()
|
||||
return result_1 + result_2
|
||||
|
||||
|
||||
def test_word_count_rust_sequential_twice_with_threads(benchmark, contents):
|
||||
executor = ThreadPoolExecutor(max_workers=2)
|
||||
count = benchmark(run_rust_sequential_twice, executor, contents, "is")
|
||||
assert count == 20000
|
||||
|
|
|
|||
|
|
@ -1,14 +1,18 @@
|
|||
from .word_count import WordCounter, count_line
|
||||
from .word_count import search, search_sequential, search_sequential_allow_threads
|
||||
|
||||
__all__ = ["WordCounter", "count_line", "search_py"]
|
||||
__all__ = [
|
||||
"search_py",
|
||||
"search",
|
||||
"search_sequential",
|
||||
"search_sequential_allow_threads",
|
||||
]
|
||||
|
||||
|
||||
def search_py(path, needle):
|
||||
def search_py(contents, needle):
|
||||
total = 0
|
||||
with open(path, "r") as f:
|
||||
for line in f:
|
||||
words = line.split(" ")
|
||||
for word in words:
|
||||
if word == needle:
|
||||
total += 1
|
||||
for line in contents.split():
|
||||
words = line.split(" ")
|
||||
for word in words:
|
||||
if word == needle:
|
||||
total += 1
|
||||
return total
|
||||
|
|
|
|||
|
|
@ -132,7 +132,6 @@ about this topic.
|
|||
|
||||
## Examples
|
||||
|
||||
* [examples/word-count](examples/word-count) _Counting the occurrences of a word in a text file_
|
||||
* [hyperjson](https://github.com/mre/hyperjson) _A hyper-fast Python module for reading/writing JSON data using Rust's serde-json_
|
||||
* [html-py-ever](https://github.com/PyO3/setuptools-rust/tree/master/html-py-ever) _Using [html5ever](https://github.com/servo/html5ever) through [kuchiki](https://github.com/kuchiki-rs/kuchiki) to speed up html parsing and css-selecting._
|
||||
* [point-process](https://github.com/ManifoldFR/point-process-rust/tree/master/pylib) _High level API for pointprocesses as a Python library_
|
||||
|
|
|
|||
|
|
@ -1,66 +1,75 @@
|
|||
# Parallelism
|
||||
|
||||
CPython has the infamous GIL (Global Interpreter Lock), which prevents developers
|
||||
from getting true parallelism when running pure Python code. While PyO3 needs to
|
||||
hold the GIL by default when called from Python, in order to allow manipulation
|
||||
of Python objects, you can release the GIL when executing Rust-only code to
|
||||
achieve true parallelism.
|
||||
CPython has the infamous [Global Interpreter Lock](https://docs.python.org/3/glossary.html#term-global-interpreter-lock), which prevents several threads from executing Python bytecode in parallel. This makes threading in Python a bad fit for [CPU-bound](https://stackoverflow.com/questions/868568/) tasks and often forces developers to accept the overhead of multiprocessing.
|
||||
|
||||
The [`Python::allow_threads`] method temporarily releases the GIL, thus allowing other Python threads to run.
|
||||
|
||||
```rust,ignore
|
||||
impl Python {
|
||||
pub fn allow_threads<T, F>(self, f: F) -> T where F: Send + FnOnce() -> T {}
|
||||
In PyO3 parallelism can be easily achieved in Rust-only code. Let's take a look at our [word-count](https://github.com/PyO3/pyo3/blob/master/examples/word-count/src/lib.rs) example, where we have a `search` function that utilizes the [rayon](https://github.com/nikomatsakis/rayon) crate to count words in parallel.
|
||||
```rust, ignore
|
||||
#[pyfunction]
|
||||
fn search(contents: &str, needle: &str) -> usize {
|
||||
contents
|
||||
.par_lines()
|
||||
.map(|line| count_line(line, needle))
|
||||
.sum()
|
||||
}
|
||||
```
|
||||
|
||||
Let's take a look at our [word-count](https://github.com/PyO3/pyo3/blob/master/examples/word-count/src/lib.rs) example,
|
||||
where we have a `wc_parallel` function that utilizes the [rayon](https://github.com/nikomatsakis/rayon) crate to count words in parallel.
|
||||
|
||||
```rust,ignore
|
||||
fn wc_parallel(lines: &str, search: &str) -> i32 {
|
||||
lines.par_lines()
|
||||
.map(|line| wc_line(line, search))
|
||||
.sum()
|
||||
But let's assume you have a long running Rust function which you would like to execute several times in parallel. For the sake of example let's take a sequential version of the word count:
|
||||
```rust, ignore
|
||||
fn search_sequential(contents: &str, needle: &str) -> usize {
|
||||
contents.lines().map(|line| count_line(line, needle)).sum()
|
||||
}
|
||||
```
|
||||
|
||||
Then in the Python bridge, we have a function `search` exposed to the Python runtime which calls
|
||||
`wc_parallel` inside a closure passed to [`Python::allow_threads`] to enable true parallelism:
|
||||
|
||||
```rust,ignore
|
||||
#[pymodule]
|
||||
fn word_count(py: Python, m: &PyModule) -> PyResult<()> {
|
||||
|
||||
#[pyfn(m, "search")]
|
||||
fn search(py: Python, path: String, search: String) -> PyResult<i32> {
|
||||
let mut file = File::open(path)?;
|
||||
let mut contents = String::new();
|
||||
file.read_to_string(&mut contents)?;
|
||||
|
||||
let count = py.allow_threads(move || wc_parallel(&contents, &search));
|
||||
Ok(count)
|
||||
}
|
||||
|
||||
Ok(())
|
||||
To enable parallel execution of this function, the [`Python::allow_threads`] method can be used to temporarily release the GIL, thus allowing other Python threads to run. We then have a function exposed to the Python runtime which calls `search_sequential` inside a closure passed to [`Python::allow_threads`] to enable true parallelism:
|
||||
```rust, ignore
|
||||
#[pyfunction]
|
||||
fn search_sequential_allow_threads(py: Python, contents: &str, needle: &str) -> usize {
|
||||
py.allow_threads(|| search_sequential(contents, needle))
|
||||
}
|
||||
```
|
||||
|
||||
Now Python threads can use more than one CPU core, resolving the limitation which usually makes multi-threading in Python only good for IO-bound tasks:
|
||||
```Python
|
||||
from concurrent.futures import ThreadPoolExecutor
|
||||
from word_count import search_sequential_allow_threads
|
||||
|
||||
executor = ThreadPoolExecutor(max_workers=2)
|
||||
|
||||
future_1 = executor.submit(
|
||||
word_count.search_sequential_allow_threads, contents, needle
|
||||
)
|
||||
future_2 = executor.submit(
|
||||
word_count.search_sequential_allow_threads, contents, needle
|
||||
)
|
||||
result_1 = future_1.result()
|
||||
result_2 = future_2.result()
|
||||
```
|
||||
|
||||
## Benchmark
|
||||
|
||||
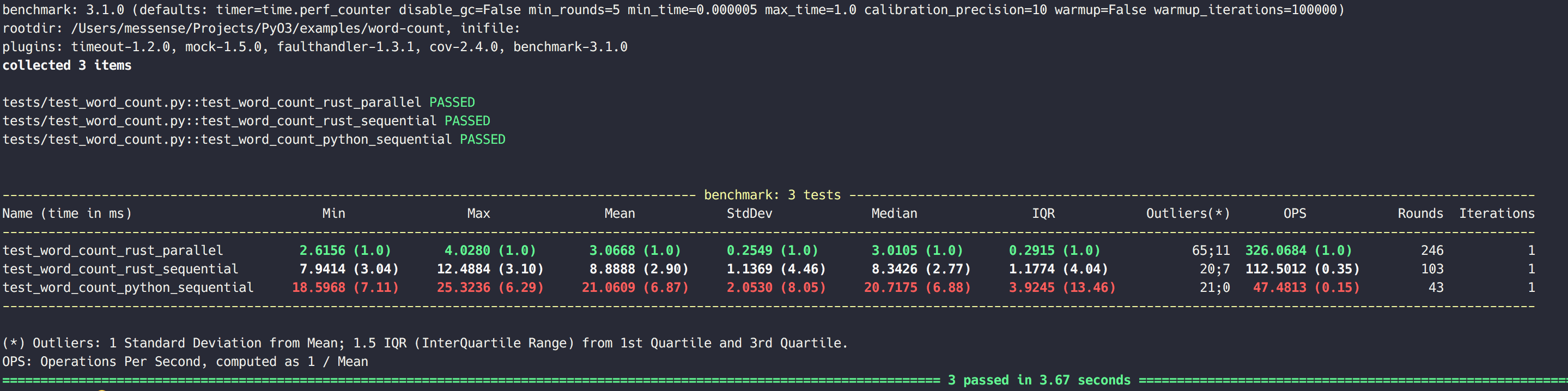
Let's benchmark the `word-count` example to verify that we did unlock true parallelism with PyO3.
|
||||
We are using `pytest-benchmark` to benchmark three word count functions:
|
||||
Let's benchmark the `word-count` example to verify that we really did unlock parallelism with PyO3.
|
||||
|
||||
1. [Pure Python version](https://github.com/PyO3/pyo3/blob/master/examples/word-count/word_count/__init__.py#L9)
|
||||
2. [Rust sequential version](https://github.com/PyO3/pyo3/blob/master/examples/word-count/src/lib.rs#L64)
|
||||
3. [Rust parallel version](https://github.com/PyO3/pyo3/blob/master/examples/word-count/src/lib.rs#L54)
|
||||
We are using `pytest-benchmark` to benchmark four word count functions:
|
||||
|
||||
The benchmark script can be found [here](https://github.com/PyO3/pyo3/blob/master/examples/word-count/tests/test_word_count.py),
|
||||
then we can run `pytest tests` to benchmark them.
|
||||
1. Pure Python version
|
||||
2. Rust parallel version
|
||||
3. Rust sequential version
|
||||
4. Rust sequential version executed twice with two Python threads
|
||||
|
||||
On MacBook Pro (Retina, 15-inch, Mid 2015) the benchmark gives:
|
||||
The benchmark script can be found [here](https://github.com/PyO3/pyo3/blob/master/examples/word-count/tests/test_word_count.py), and we can run `tox` in the `word-count` folder to benchmark these functions.
|
||||
|
||||
|
||||
While the results of the benchmark of course depend on your machine, the relative results should be similar to this (mid 2020):
|
||||
```ignore
|
||||
-------------------------------------------------------------------------------------------------- benchmark: 4 tests -------------------------------------------------------------------------------------------------
|
||||
Name (time in ms) Min Max Mean StdDev Median IQR Outliers OPS Rounds Iterations
|
||||
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
|
||||
test_word_count_rust_parallel 1.7315 (1.0) 4.6495 (1.0) 1.9972 (1.0) 0.4299 (1.0) 1.8142 (1.0) 0.2049 (1.0) 40;46 500.6943 (1.0) 375 1
|
||||
test_word_count_rust_sequential 7.3348 (4.24) 10.3556 (2.23) 8.0035 (4.01) 0.7785 (1.81) 7.5597 (4.17) 0.8641 (4.22) 26;5 124.9457 (0.25) 121 1
|
||||
test_word_count_rust_sequential_twice_with_threads 7.9839 (4.61) 10.3065 (2.22) 8.4511 (4.23) 0.4709 (1.10) 8.2457 (4.55) 0.3927 (1.92) 17;17 118.3274 (0.24) 114 1
|
||||
test_word_count_python_sequential 27.3985 (15.82) 45.4527 (9.78) 28.9604 (14.50) 4.1449 (9.64) 27.5781 (15.20) 0.4638 (2.26) 3;5 34.5299 (0.07) 35 1
|
||||
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
|
||||
```
|
||||
|
||||
You can see that the Python threaded version is not much slower than the Rust sequential version, which means compared to an execution on a single CPU core the speed has doubled.
|
||||
|
||||
[`Python::allow_threads`]: https://docs.rs/pyo3/latest/pyo3/struct.Python.html#method.allow_threads
|
||||
|
|
|
|||
Loading…
Reference in New Issue