* Fix compilation on Android with GNU STL
GNU STL in Android NDK lacks string conversion functions from C++11, including std::stoul, std::stoi, and std::stod.
This patch reimplements these functions in benchmark:: namespace using C-style equivalents from C++03.
* Avoid use of log2 which doesn't exist in Android GNU STL
GNU STL in Android NDK lacks log2 function from C99/C++11.
This patch replaces their use in the code with double log(double) function.
* format all documents according to contributor guidelines and specifications
use clang-format on/off to stop formatting when it makes excessively poor decisions
* format all tests as well, and mark blocks which change too much
As @dominichamon and I have discussed, the current reporter interface
is poor at best. And something should be done to fix it.
I strongly suspect such a fix will require an entire reimagining
of the API, and therefore breaking backwards compatibility fully.
For that reason we should start deprecating and removing parts
that we don't intend to replace. One of these parts, I argue,
is the CSVReporter. I propose that the new reporter interface
should choose a single output format (JSON) and traffic entirely
in that. If somebody really wanted to replace the functionality
of the CSVReporter they would do so as an external tool which
transforms the JSON.
For these reasons I propose deprecating the CSVReporter.
The first problem you have to solve yourself. The second one can be aided.
The benchmark library can compute some statistics over the repetitions,
which helps with grasping the results somewhat.
But that is only for the one set of results. It does not really help to compare
the two benchmark results, which is the interesting bit. Thankfully, there are
these bundled `tools/compare.py` and `tools/compare_bench.py` scripts.
They can provide a diff between two benchmarking results. Yay!
Except not really, it's just a diff, while it is very informative and better than
nothing, it does not really help answer The Question - am i just looking at the noise?
It's like not having these per-benchmark statistics...
Roughly, we can formulate the question as:
> Are these two benchmarks the same?
> Did my change actually change anything, or is the difference below the noise level?
Well, this really sounds like a [null hypothesis](https://en.wikipedia.org/wiki/Null_hypothesis), does it not?
So maybe we can use statistics here, and solve all our problems?
lol, no, it won't solve all the problems. But maybe it will act as a tool,
to better understand the output, just like the usual statistics on the repetitions...
I'm making an assumption here that most of the people care about the change
of average value, not the standard deviation. Thus i believe we can use T-Test,
be it either [Student's t-test](https://en.wikipedia.org/wiki/Student%27s_t-test), or [Welch's t-test](https://en.wikipedia.org/wiki/Welch%27s_t-test).
**EDIT**: however, after @dominichamon review, it was decided that it is better
to use more robust [Mann–Whitney U test](https://en.wikipedia.org/wiki/Mann–Whitney_U_test)
I'm using [scipy.stats.mannwhitneyu](https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.mannwhitneyu.html#scipy.stats.mannwhitneyu).
There are two new user-facing knobs:
```
$ ./compare.py --help
usage: compare.py [-h] [-u] [--alpha UTEST_ALPHA]
{benchmarks,filters,benchmarksfiltered} ...
versatile benchmark output compare tool
<...>
optional arguments:
-h, --help show this help message and exit
-u, --utest Do a two-tailed Mann-Whitney U test with the null
hypothesis that it is equally likely that a randomly
selected value from one sample will be less than or
greater than a randomly selected value from a second
sample. WARNING: requires **LARGE** (9 or more)
number of repetitions to be meaningful!
--alpha UTEST_ALPHA significance level alpha. if the calculated p-value is
below this value, then the result is said to be
statistically significant and the null hypothesis is
rejected. (default: 0.0500)
```
Example output:
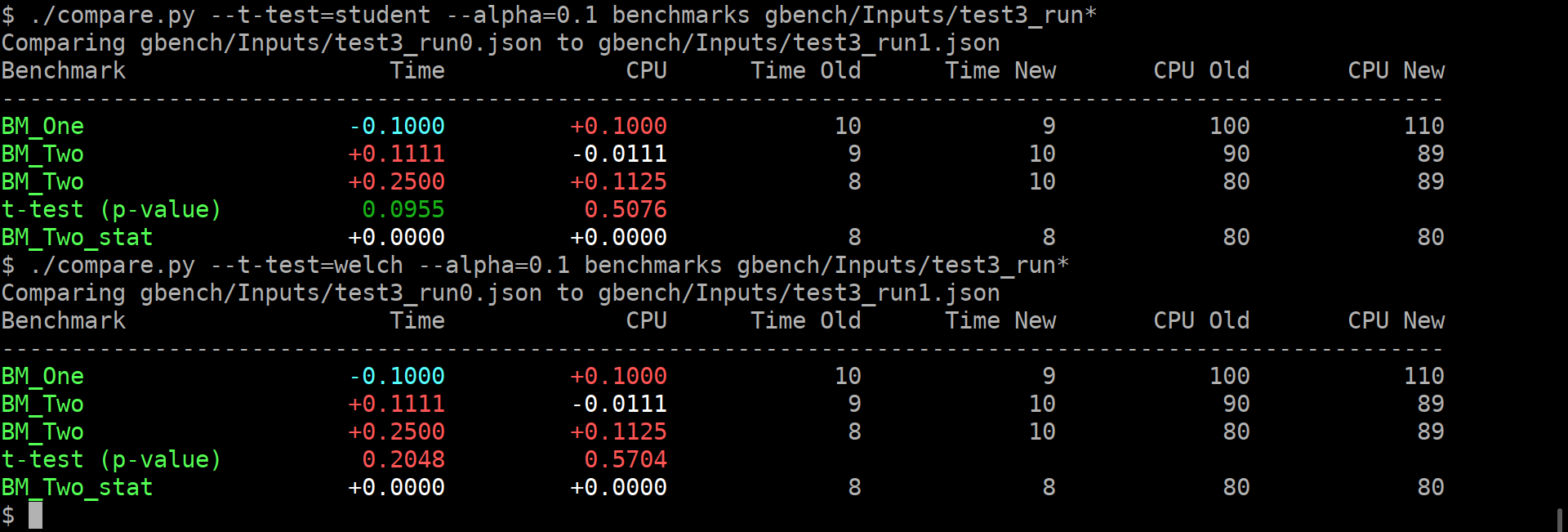
As you can guess, the alpha does affect anything but the coloring of the computed p-values.
If it is green, then the change in the average values is statistically-significant.
I'm detecting the repetitions by matching name. This way, no changes to the json are _needed_.
Caveats:
* This won't work if the json is not in the same order as outputted by the benchmark,
or if the parsing does not retain the ordering.
* This won't work if after the grouped repetitions there isn't at least one row with
different name (e.g. statistic). Since there isn't a knob to disable printing of statistics
(only the other way around), i'm not too worried about this.
* **The results will be wrong if the repetition count is different between the two benchmarks being compared.**
* Even though i have added (hopefully full) test coverage, the code of these python tools is staring
to look a bit jumbled.
* So far i have added this only to the `tools/compare.py`.
Should i add it to `tools/compare_bench.py` too?
Or should we deduplicate them (by removing the latter one)?
* Add benchmark_main library with support for Bazel.
* fix newline at end of file
* Add CMake support for benchmark_main.
* Mention optionally using benchmark_main in README.
* Correct/clarify build/install instructions
GTest is google test, don't obsfucate needlessly for newcomers.
Adding google test into installation guide helps newcomers.
Third option under this line: "Note that Google Benchmark requires Google Test to build and run the tests. This
dependency can be provided three ways:"
Was not true (did not occur). If there is a further option that needs to be specified in order for that functionality to work it needs to be specified.
* Add prerequisite knowledge section
A lot of assumptions are made about the reader in the documentation. This is unfortunate.
* Removal of abbreviations for google test
Git was being executed in the current directory, so could not get the
latest tag if cmake was run from a build directory. Force git to be
run from with the source directory.
Note, bazel only supports MSVC on Windows, and not MinGW, so
linking against shlwapi.lib only needs to follow MSVC conventions.
git_repository() did not work in local testing, so is swapped for
http_archive(). The latter is also documented as the preferred way
to depend on an external library in bazel.
* Allow support for negative regex filtering
This patch allows one to apply a negation to the entire regex filter
by appending it with a '-' character, much in the same style as
GoogleTest uses.
* Address issues in PR
* Add unit tests for negative filtering
Before this change, we would report the number of requested iterations
passed to the state. After, we will report the actual number run. As a
side-effect, instead of multiplying the expected iterations by the
number of threads to get the total number, we can report the actual
number of iterations across all threads, which takes into account the
situation where some threads might run more iterations than others.
* Ensure 64-bit truncation doesn't happen for complexity results
* One more complexity_n 64-bit fix
* Missed another vector of int
* Piping through the int64_t
* Allow AddRange to work with int64_t.
Fixes#516
Also, tweak how we manage per-test build needs, and create a standard
_gtest suffix for googletest to differentiate from non-googletest tests.
I also ran clang-format on the files that I changed (but not the
benchmark include or main src as they have too many clang-format
issues).
* Add benchmark_gtest to cmake
* Set(Items|Bytes)Processed now take int64_t
* Add tests to verify assembler output -- Fix DoNotOptimize.
For things like `DoNotOptimize`, `ClobberMemory`, and even `KeepRunning()`,
it is important exactly what assembly they generate. However, we currently
have no way to test this. Instead it must be manually validated every
time a change occurs -- including a change in compiler version.
This patch attempts to introduce a way to test the assembled output automatically.
It's mirrors how LLVM verifies compiler output, and it uses LLVM FileCheck to run
the tests in a similar way.
The tests function by generating the assembly for a test in CMake, and then
using FileCheck to verify the // CHECK lines in the source file are found
in the generated assembly.
Currently, the tests only run on 64-bit x86 systems under GCC and Clang,
and when FileCheck is found on the system.
Additionally, this patch tries to improve the code gen from DoNotOptimize.
This should probably be a separate change, but I needed something to test.
* Disable assembly tests on Bazel for now
* Link FIXME to github issue
* Fix Tests on OS X
* fix strip_asm.py to work on both Linux and OS X like targets
Having the copts set on a per-target level can lead to ODR violations
in some cases. Avoid this by ensuring the regex engine is picked
through compiler intrinsics in the header directly.
This patch disables the -Winvalid-offsetof warning for GCC and Clang
when using it to check the cache lines of the State object.
Technically this usage of offsetof is undefined behavior until C++17.
However, all major compilers support this application as an extension,
as demonstrated by the passing static assert (If a compiler encounters UB
during evaluation of a constant expression, that UB must be diagnosed).
Unfortunately, Clang and GCC also produce a warning about it.
This patch temporarily suppresses the warning using #pragma's in the
source file (instead of globally suppressing the warning in the build systems).
This way the warning is ignored for both CMake and Bazel builds without
having to modify either build system.
Older CMake versions, in particular 2.8, don't seem to correctly handle
interface include directories. This causes failures when building the
tests. Additionally, older CMake versions use a different library install
directory than expected (i.e. they use lib/<target-triple>). This caused
certain tests to fail to link.
This patch fixes both those issues. The first by manually adding the
correct include directory when building the tests. The second by specifying
the library output directory when configuring the GTest build.
* Add myself to CONTRIBUTORS under the corp CLA for Stripe, Inc.
* Add support for building with Bazel.
Limitations compared to existing CMake rules:
* Defaults to using C++11 `<regex>`, with an override via Bazel flag
`--define` of `google_benchmark.have_regex`. The TravisCI config sets
the regex implementation to `posix` because it uses ancient compilers.
* Debug vs Opt mode can't be set per test. TravisCI runs all the tests
in debug mode to satisfy `diagnostics_test`, which depends on `CHECK`
being live.
* Set Bazel workspace name so other repos can refer to it by stable name.
This is recommended by the Bazel style guide to avoid each dependent
workspace defining its own name for the dependency.
* Rename StringXxx to StrXxx in string_util.h and its users
This makes the naming consistent within string_util and moves is the
Abseil convention.
* Style guide is 2 spaces before end of line "//" comments
* Rename StrPrintF/StringPrintF to StrFormat for absl compatibility.
On Windows the Shlwapi.h file has a macro:
#define StrCat lstrcatA
And benchmark/src/string_util.h defines StrCat and it is renamed to
lstrcatA if we don't undef the macro in Shlwapi.h. This is an innocuous
bug if string_util.h is included after Shlwapi.h, but it is a compile
error if string_util.h is included before Shlwapi.h.
This fixes issue #545.
* Add Solaris support
Define BENCHMARK_OS_SOLARIS for Solaris.
Platform specific implementations added:
* number of CPUs detection
* CPU cycles per second detection
* Thread CPU usage
* Process CPU usage
* Remove the special case for per process CPU time for Solaris, it's the same as the default.
* Print the executable name as part of the context.
A common use case of the library is to run two different
versions of a benchmark to compare them. In my experience
this often means compiling a benchmark twice, renaming
one of the executables, and then running the executables
back-to-back. In this case the name of the executable
is important contextually information. Unfortunately the
benchmark does not report this information.
This patch adds the executable name to the context reported
by the benchmark.
* attempt to fix tests on Windows
* attempt to fix tests on Windows
Due to ADL lookup performed on the begin and end functions
of `for (auto _ : State)`, std::iterator_traits may get
incidentally instantiated. This patch ensures the library
can tolerate that.
* Don't include <sys/resource.h> on Fuchsia.
It doesn't support POSIX resource measurement and timing APIs.
Change-Id: Ifab4bac4296575f042c699db1ce5a4f7c2d82893
* Add BENCHMARK_OS_FUCHSIA for Fuchsia
Change-Id: Ic536f9625e413270285fbfd08471dcb6753ddad1
* Improve State packing: put important members on first cache line.
This patch does a few different things to ensure commonly accessed
data is on the first cache line of the `State` object.
First, it moves the `error_occurred_` member to reside after
the `started_` and `finished_` bools, since there was internal
padding there that was unused.
Second, it moves `batch_leftover_` and `max_iterations` further up
in the struct declaration. These variables are used in the calculation
of `iterations()` which users might call within the loop. Therefore
it's more important they exist on the first cache line.
Finally, this patch turns the bool members into bitfields. Although
this shouldn't have much of an effect currently, because padding is
still needed between the last bool and the first size_t, it should
help in future changes that require more "bool like" members.
* Remove bitfield change for now
* Move bools (and their padding) to end of "first cache line" vars.
I think it makes the most sense to move the padding required
following the group of bools to the end of the variables we want
on the first cache line.
This also means that the `total_iterations_` variable, which is the
most accessed, has the same address as the State object.
* Fix static assertion after moving bools
* Support State::KeepRunningBatch().
State::KeepRunning() can take large amounts of time relative to quick
operations (on the order of 1ns, depending on hardware). For such
sensitive operations, it is recommended to run batches of repeated
operations.
This commit simplifies handling of total_iterations_. Rather than
predecrementing such that total_iterations_ == 1 signals that
KeepRunning() should exit, total_iterations_ == 0 now signals the
intention for the benchmark to exit.
* Create better fast path in State::KeepRunningBatch()
* Replace int parameter with size_t to fix signed mismatch warnings
* Ensure benchmark State has been started even on error.
* Simplify KeepRunningBatch()
* Implement KeepRunning() in terms of KeepRunningBatch().
* Improve codegen by helping the compiler undestand dead code.
* Dummy commit for build bots' benefit.
* Attempt to fix travis timeouts during apt-get.
During some builds, travis fails to update the apt-get indexes.
This causes the build to fail in different ways.
This patch attempts to avoid this issue by manually calling
apt-get update. I'm not sure if it'll work, but it's worth a try.
* Fix missing semicolons in command
{kind=link}